I have worked in numerous companies and roles over the past 15+ years. Culture and behaviour are a symptom of the system.
I will level with you; I do not like job roles or titles they are symptom of the system. More specifically I now consider myself a problem solver – even though this is a role, whether that be Front End, Back End, DevOps, QA, BA, PM, coach, leader, mentor, etc. I will do any role that needs fulfilling to ship valuable working software to the customer. I have got areas of specialism, areas I am ok at and areas where I need to read and learn. However, on a personal note I love learning new technology and techniques.
Back to the system, if you create a system with job roles – more specifically the trend that I see now is the split between Front End vs. Back End & the new Full Stack role and the more traditional QA engineer or DevOps engineer. That is the system, people’s behaviours will start to align with the roles. For example – ask a DevOps engineer to do some React or Angular in this system and the likely hood is that you will get push back. That is not my role, I’m employed as a DevOps engineer and all I do is Terraform and AWS!
Delivering working software does not occur in a silo of work, do Front End then Back End – at any point you could be a stakeholder, PM, PO, BA, Front End, Back End, QA, DevOps, Release Engineer, etc.
My experience of highly successful teams – read delivering valuable software to customers, with short lead times. Is that most team members will be needed to fulfill any role while delivering software.
Having push back just creates queues and expands lead times. Oh, the Front End dev’s just finished the UI, but the Back End component isn’t ready. Software sits there waiting in a queue before the Back End work is done. Queues kill flow.
I first came across the idea of story slicing at Agile North when Seb Rose ran a workshop about it. Our primary goal was to slice a story for a twitter clone from memory this was the ability to post a tweet of 120 chars. I recall during the exercise we never quite sliced thinly enough, with Seb always challenging us to slice thinner. Eventually the initial slice was just a web page with a text box to enter some text no restrictions. I thought at the time this slice was way too thin, with little or no value – I really struggled to understand slicing so aggressively.
I’ve tried over the last 4 or 5 years to understand slicing and apply it more in my every day to work. Some environments allow this, and some don’t.
The example that I’ve come up across recently is getting the product information for a product on an ecommerce site from a different place. This is my attempt at slicing it thinly:
Pick a single product
Feature switch getting the title for the view from existing location to be hard coded in the view
Push back the hard coding back through the architecture – i.e. this might be calling a api to retrieve the data
Manually enter the title in to the product store & retrieve from there
Each slice should be deployed and monitored. There are other tasks contained in each of these thin slices – like monitoring and setting up deployment pipelines potentially. However, these steps shouldn’t take that long.
By slicing this thinly you can learn about your architecture and get the walking skelton in place relatively quickly. Therefore, understanding if you have any issues with the path you are taking.
You could then expand this out to another product or build out some other capability.
The take home is try to half what you do now, then once you get good at that, half it again. You should aim to get something delivered every day which extends your understanding of the problem domain.
My car went in to be serviced today, my wife takes it to the garage.
So that means I usually leave a note, if there are other problems with it. I’ve had an issue with my front head light. Last time I talked to them about it, they said it would probably be the bulb. I’d proved this not to be the case by changing the bulb from one head light to the other. I had to hand this information off, so I wrote a note.
During the day I got a call from the garage. The guy on the line wasn’t the mechanic doing the work, we had a garbled conversation about what the problem was, and what my note really meant. After about 2 minutes of not getting anywhere, he put the mechanic doing the work on. I managed to explain the investigation work I’d done, and my (google car expert) diagnosis of the issue.
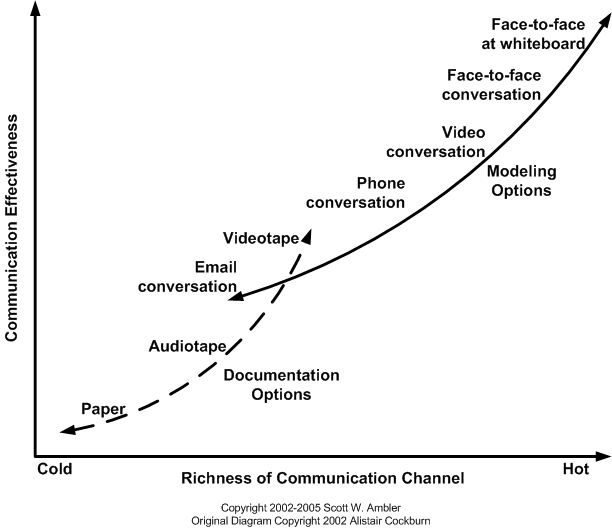
As my drive can be long home, I began to wonder about what had happened. It got me thinking about this diagram:
This has a couple of things:
I’d done some initial work – investigation and tried to express this in a note (hand off). Which was useless, it was only useful as a conversation starter. Maybe my badly written note would have been better “Front Headlight not working please call me”, rather than trying to describe what I’d done to investigate.
Why it’s important to talk to the person doing the work instead of a middle person.
Would it have been quicker face to face, with the car in front of both of us, to discuss.
We recently had some work to do which focused on getting stock more real time on the website. Here I’m going to take you on the journey of this piece of work.
We started with the above “requirement”, the real problem however, was subtle different – overselling on the website. This has the following impact on the customer and business:
The customer is annoyed because the order is cancelled, because it can’t be fulfilled
The cancellation process is slow, and is time consuming for Customer Services.
So how does stock get on the website? Stock is calculated every 5 minutes with a batch job then read in two ways on the website:
Through our search system
Through a direct call to our ERP system
The first slice was to make stock come from a single source, this would be easier to change in the future. So we set about reading the data directly from the ERP system and publishing this to our new stock service, then subsequently reading it in the website. This was live for a brand within a day or two. There was still some latency in this as we were still reliant on another batch job finishing before reading directly from the ERP system.
While delivering something quickly, this was the wrong slice as we didn’t really understand how we much we oversold by or when it happened (more on this later).
We started on the second obvious slice, making the stock real tiem, as we were still reliant on the batch job finishing for our stock levels to be up to date. We decided to “baseline” our stock and then just deal with “goods out” – i.e. what was sold on the site.
During this second slice, which was now much bigger, and more complicated. There were some product launches – this meant we had an opportunity to measure the impact of what we had been doing. We quickly realised that this second slice was wrong as we couldn’t measure the impact of it.
We pivoted to what our first slice should have been – understand overselling. We created numerous apps to let us monitor during these product launches so we could understand overselling. These where manual and needed us to watch them run. So after the first product launch, once we were happy this data was trustworthy. We enhanced these to not have to be manually run, so we monitor oversells and unknown product sales 24/7 now. We also started to capture when people entered the checkout on the website.
From this we could see a number of things about overselling:
About 80% of people where in our checkout; once we’d sold out
About 15% of people where still shopping on the site; once we’d sold out
About 5% where due to the non-real time nature of stock
Even if we’d completed our original second slice – “real time stock” we wouldn’t have solved the problem – overselling!
We came up with a list of things we could do, and worked with the stakeholder to narrow it down to the following:
Before placing the order – do a stock check
When people enter the checkout – do a stock check
Unfortunately, we’d already made another improvement which we didn’t know the impact of. Making the stock come from a single place. This was quantifiable as we’d not been measuring before we’d made any changes.
We made the changes outlined above and continuously released them and tried to monitor their impact.
We had some bad/good luck our new stock service started failing just before the weekend, so we had to turn it off. This was a blessing as we could now see how the site actually performed without any of our changes. Below is overselling over the weekend:
The coming weeks will be interesting as there are product launches, which tend to increase our overselling. Our plan is to monitor these and see if we need to do any more work.
Some things we learned:
Metrics – understand the problem & measure the impact of changes
Pivot quickly
Deliver every commit
Logging in apps – understand what your applications are doing, business and application wise
Well I managed to get out to Lean Agile Manchester last night about Workplace visualisation and catch up with Carl Phillips of ao. We had an excellent burger in the Northern Quarter before heading over to madlab, therefore delaying our arrival – oops sorry guys! We spent quite a bit of time chatting about old times & then got down to the problem at hand.
Weirdly the first example was very reminiscent of where Carl & I started our journey at ao nearly four years ago. Although, some of the key points where slightly different – i.e. number of developers, the location of the constraints in the department.
A rough guide of the scenario:
Specialists with hand-offs, bottleneck in test, multi-tasking galore
Small changes and incidents getting in the way of more strategic projects
4 devs, 1 QA, 1 BA
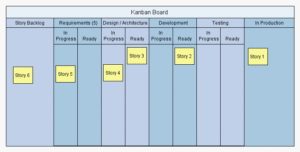
We came up with a board similar to this:
We introduced WIP limits around the requirements section and set this at 1 as testing tended to be the bottleneck. Reflecting this morning – introducing the WIP limits might have been a little premature…
As we where happy with the previous board, Ian challenged us to look at the digital agency scenario.
We started to map out the current value stream for the digital agency. A rough guide for the scenario:
Multitasking on client projects, fixed scope and deadlines,
lots of rework particularly because of UX
lots of late changes of requirements
3rd party dependencies and a long support handover for client projects
4 devs, 1 QA, 1 BA
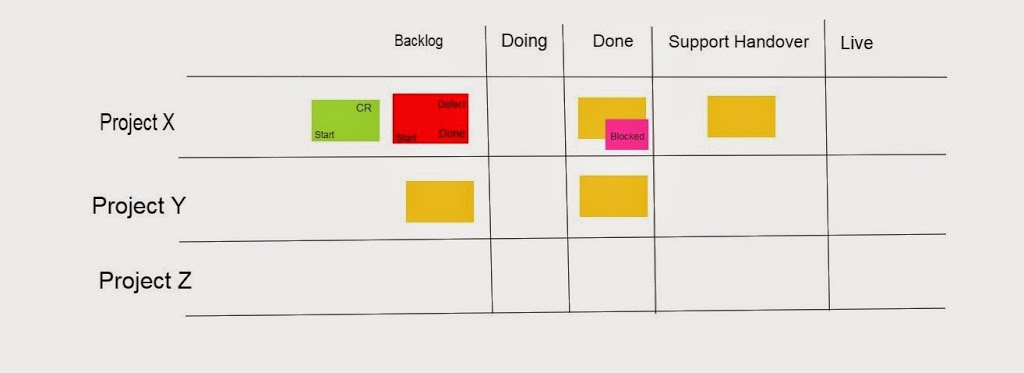
This time we used swim lanes. It looked similar but not exactly like this:
These actually added inherent WIP limits because a swim lane could only have one card in within the column. We introduced different two additional classes of service (we had a “feature” class of service for project work):
A defect which blocked the current ticket and got tracked across the board.
CR’s which would track across the board too.
We had a differing opinion on whether the “client support hand over” should be an additional column or a ticket – we ended up going with a column.
What I realised about this second scenario was that we mapped what was currently happening, although we introduced some inherent WIP limits due to board layout, but these where not forced upon the board – i.e. with numbers above the card columns.
Visualisation is good first step on understanding how work flows through a system, but remember to not force concepts on to the current environment. “Start with what you do now”.
No this is not a post about music. It’s about software development and more importantly delivery.
Before I progress we are all agreed that we are mammals, therefore have an inbuilt rhythm – http://en.wikipedia.org/wiki/Circadian_rhythm – this is usually a 24/25 hour period in which we all sleep, wake, eat and go to work or do something else!
So let’s elaborate further and take this in to the realm of software delivery. It appears that we (mammals) need rhythm – “Although circadian rhythms are endogenous (“built-in”, self-sustained), they are adjusted (en-trained) to the local environment by external cues called zeitgebers, commonly the most important of which is daylight.”.
This is where software delivery comes in, I’d like to take SCRUM as the example of setting up this rhythm. Every 2 weeks we’ll deliver software, have some planning and retrospect. This sets the pace for the delivery – team members know when things are happening and therefore can get in to a rhythm. The team understands when the start and end is – they have a focus too for a given time period.
Now I’m an advocate of delivering more often (every couple of days), but I believe that until you can do these things well which is walking, you can’t sprint (no pun intended).
The other rhythm is that of the daily stand up – this occurs at the same place & time each day.
Other Agile practices seem to promote the same ideas – such as the TDD cycle, pair programming (if you pair well – i.e. swapping the keyboard!!).
It appears that with no rhythm you’ll deliver software, but maybe you won’t be going as quickly as you can.
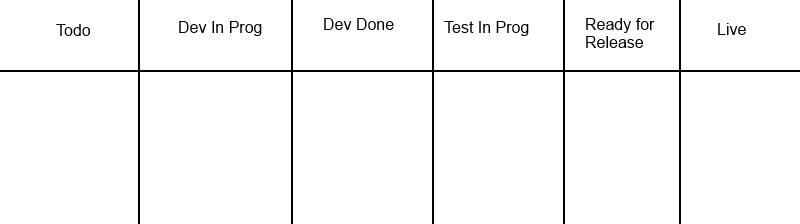
Below is a pretty much “default” Kanban board & the relevant columns. We still use CFD’s to analyse & hopefully improve flow through our system. So what I’ve been pondering is whether the below is right for us.
We have 2 main queues that I want to talk about today. The Dev Done & the Ready for Release. I’m going to focus on the right side of the board to start with as this is the most valuable side…
What we tend to see over our sprints is a build up towards the end of the sprint. I’m now pondering the benefit of the Ready for Release column. Over time stories/work builds up here and is not release. Part of my limited WIP side comes in to play as well, as soon as I see more than 3/4 cards in play. I’m probably thinking a little bit about the size of the release and the riskiness of the release too.
So this is starting to make me question:
Is this really a good column to have?
Why are we completing stuff in test then not releasing it straight away? Maybe the transaction cost to live is too much, if this is the case then this is the problem that needs to be highlighted and gone after.
Are the stories not valuable to be released independently and maybe the relative value of them is not important?
I’m also questioning the benefit of any queues in the system – like the one between Dev Done & Test. It seems as though this is a smell rather than a solution to flowing work through the system. Queues are just a way to buffer another piece of the system from inconsistent flow of work, most of the work on the board can be controlled by the team. We have cross functional dedicated teams, therefore they should be able to “dev & test” in a single flow.
Some may say that the start of the system is a queue, but in fact this is simply an input buffer to the system/team. This helps to prevent variance within the system so that there is always enough work for the team to work on. Therefore, my opinion is that this is “required”.
I watched an excellent video by Ken Schwaber the other day regarding SCRUM. Like all these things certain stuff just resonated with me…
One of the key points was how tough SCRUM was to implement and the relative poor success rate in implementing SCRUM. The reason behind this is due to the tough questions that SCRUM highlights, my firm belief is that “Agile methodologies” like SCRUM, Kanban, etc do exactly this on the tin. Highlight your problems – I recall a quote, “It’s like developing software in a room with all the lights full blast, compared to the dark room you’ve been sat in for last 5 years!”
People often see “Agile methodologies” as silver bullets – follow some simple rules and this will change your software development process for the better. I mean what else could be simpler? It will make you able to accept changing requirements late in the build process, build better quality and deliver faster. The honest truth is that just following these simple rules won’t help your process. The reason you’re looking for a change is usually because of the three reasons highlighted.
You’ve got to accept that there are going to be some really tough questions that are highlighted.
You’ve got to accept that you have to answer these questions to be successful.
Only you can answer these questions, not anybody else.
If you’re scared of answering tough questions and having tough conversations then do not engage with these “methodologies”. Or if you do then be prepared to fail.
So who is “you” – it’s everyone from the top to the bottom.
The answers to these questions will inevitably lead to change, and once again this change has to be done in the correct manner. Embracing change, and ensuring that everyone is happy with the change is extremely hard to do – it needs time and effort from people. It needs people to address people’s concerns, discuss why the change is better than the status quo.
There are better articles about managing change at the following locations:
Last night’s XPMan was really good. We did some TDD but with no code – essentially we created tests and then created a sequence diagram to pass the tests. We then applied the RGR (Red, Green, and Refactor) to the sequence diagram as we built up the tests; I found it a really good exercise in returning to the basics of TDD. One key thing for me was that it’s really important to do the simplest thing first and get this to go red before you do anything overly complex. During the second kata and my second pair of the evening this became quite pertinent.
However, there is one discussion which provoked some thought and quite a heated exchange. This came in the form of, “I’m a code monkey and I should just fulfil the requirements given to me by the BA’s/customers.” This provoked quite a debate about if a BA asked you to jump of a build would you do it? Another comment was about reading the Agile Manifesto.
So here’s my 50p worth. Yes I am a code monkey, but professionally I need to question what I’m doing. However, this has to be done in the correct manner – asking what the business value is of a specific requirement/user story is? Rather than just saying no. By asking this question – you are just ensuring that the person asking for the work to be done has considered whether it is valuable. If the answer is yes, then you have to fulfil this obligation to the customer and complete the requirement/user story even if you deem it as spurious. This is the professional thing to do.
It’s really important not to blindly accept what people are telling you what to do, but to ask questions and occasionally say no in the right manner – but the manner in saying no has nothing to do with the Agile Manifesto, more the way you say it.
Maybe an unrelated thing – the Agile Manifesto say’s that we value the things on the left more than the right – but remember the things on the right we still value. Something I sometimes forget about is that we still need a plan, we still need a contract negotiation – it’s just we value the following changing requirements & customer collaboration over the other two.
So yes I am a code monkey, but it’s important to question what you’re doing before committing to it.
I recently asked the following question – What does good team code ownership look like?
Everyone adding (good) test coverage
Discussing the code
Design strategy
Adhere to code standards
Tool box of patterns
Everyone adding (good) test coverage
This is especially important, tests make everyone feel secure when making changes to the code base. Everyone in the team must know the benefits of tests, so must maintain them and add other good tests.
Discussing the Code
The code is essentially a living entity, i.e. we add functionality, we have to look after it, it is often sick! So it’s important that the team talks about the code base. This is powerful because it gives people are deeper understanding of the code base.
Design strategy
A way to improve the design – most code bases have areas that don’t give us the necessary ways to change the code, or they are hard to test. So they need to be refactored & improved upon. We are currently doing this with our UI – using MVP.
Adhere to code standards
Currently we don’t have any standards, however, I do think we have a good code style. This is mainly garnered from Uncle Bob’s clean code videos – which are excellent by the way – you should watch them if you’ve not (or read his book Clean Code)!
Toolbox of Patterns
You’ve got to be able to change the code, this becomes linked to discussing the code. Patterns can help with discussing the code… Having a design strategy – links to this!
This is not a comprehensive list but it’s a good start…
Remember: “It’s important not to own code you’ve written in a code base; however it’s important that people respect the way the code was written”