I have worked in numerous companies and roles over the past 15+ years. Culture and behaviour are a symptom of the system.
I will level with you; I do not like job roles or titles they are symptom of the system. More specifically I now consider myself a problem solver – even though this is a role, whether that be Front End, Back End, DevOps, QA, BA, PM, coach, leader, mentor, etc. I will do any role that needs fulfilling to ship valuable working software to the customer. I have got areas of specialism, areas I am ok at and areas where I need to read and learn. However, on a personal note I love learning new technology and techniques.
Back to the system, if you create a system with job roles – more specifically the trend that I see now is the split between Front End vs. Back End & the new Full Stack role and the more traditional QA engineer or DevOps engineer. That is the system, people’s behaviours will start to align with the roles. For example – ask a DevOps engineer to do some React or Angular in this system and the likely hood is that you will get push back. That is not my role, I’m employed as a DevOps engineer and all I do is Terraform and AWS!
Delivering working software does not occur in a silo of work, do Front End then Back End – at any point you could be a stakeholder, PM, PO, BA, Front End, Back End, QA, DevOps, Release Engineer, etc.
My experience of highly successful teams – read delivering valuable software to customers, with short lead times. Is that most team members will be needed to fulfill any role while delivering software.
Having push back just creates queues and expands lead times. Oh, the Front End dev’s just finished the UI, but the Back End component isn’t ready. Software sits there waiting in a queue before the Back End work is done. Queues kill flow.
I’ve been doing quite a bit of work with Terraform & Azure recently. One requirement is to use Nginx with SSL termination. Rather than buy a certificate all the time I chose to use https://letsencrypt.org/ which plugs nicely in to nginx.
I’ve used cloud init config to install nginx and certbot which essentially create & retrieves certificates from LetsEncrypt and updates the nginx config with the relevant entries. There is also a cron.d job which runs to update the certificates whenever they are close to expiring, LetsEncrypt certificates expire in 90 days.
We then need to create the nginx.conf setup for the site. I’ve snipped the rest of the nginx.conf – the important bit is that we have the server_name to match the domain we are issuing the certificate to.
When running TeamCity in docker, I recently had to setup ssh with Mercurial on Bitbucket.org which isn’t built in to TeamCity.
This is so I don’t forgot how I did it! Ideally you could do this with your own container – which is a better option!
SSH to the TeamCity Server
Type sudo docker ps
Type sudo docker exec -it xxx (your container id) /bin/bash
Type apt-get install vim
Type cd ~/.ssh
Type touch teamcity
Type vim teamcity
Add the private ssh key – using the Open-SSH key format – that you want to communicate with Mercurial – you should add the public key to Bitbucket.org.
Save the file
Type touch config
Add the following: Host bitbucket.org
IdentityFile ~/.ssh/teamcity
Save the file
Type chmod 400 ~/.ssh/teamcity
Type ssh hg@bitbucket.org
Accept the thumbprint – you should see that you can connect
Type exit
You should be able to connect via ssh to your Mercurial repository from TeamCity now!
TeamCity should have the following in the
Pull Changes From url: ssh://bitbucket.org/repository
Username: hg
Password:
The ability to deliver code all the time, sounds magically. I propose most companies aren’t that far from enabling this within their development teams and even their legacy code bases. One of the most common arguments against is that we don’t have enough automated tests to continuously deliver.
I’d argue that the 4 things you need to enable continuous delivery are:
continuous integration
a minimum of 2 automated tests
monitoring
blue green deployment setup
The most important is the ability to monitor the changes going to live. A good start is something like NewRelic which is easy to install on production boxes and gives a good feeling for whether your application is healthy or not.
When talking about automated tests, my preference is to test the most important part of your journey. For an ecommerce site this would be placing an order as a guest. Then the second test might be placing an order as a signed in user. My maximum for these kind of tests (if you are thinking Selenium) is around 5 at the most. Once you have these tests in your build pipeline you are a step closer to continuously deployment.
Finally having a blue, green setup for deployment is essential, so if the monitoring is showing you a change has broken something you can simply revert quickly. Then fix and re-deploy as quickly as possible.
There is obviously a caveat to this, try to start deploying smaller increments to live – ideally one changeset. Then if something goes wrong you know what has broken it.
I don’t propose no Test Driven Development, or no testing.
I’m just proposing that it’s not as hard as you think it is to get to a point where you can continuously deliver software. I consider continuous delivery to be an ability.
I first came across the idea of story slicing at Agile North when Seb Rose ran a workshop about it. Our primary goal was to slice a story for a twitter clone from memory this was the ability to post a tweet of 120 chars. I recall during the exercise we never quite sliced thinly enough, with Seb always challenging us to slice thinner. Eventually the initial slice was just a web page with a text box to enter some text no restrictions. I thought at the time this slice was way too thin, with little or no value – I really struggled to understand slicing so aggressively.
I’ve tried over the last 4 or 5 years to understand slicing and apply it more in my every day to work. Some environments allow this, and some don’t.
The example that I’ve come up across recently is getting the product information for a product on an ecommerce site from a different place. This is my attempt at slicing it thinly:
Pick a single product
Feature switch getting the title for the view from existing location to be hard coded in the view
Push back the hard coding back through the architecture – i.e. this might be calling a api to retrieve the data
Manually enter the title in to the product store & retrieve from there
Each slice should be deployed and monitored. There are other tasks contained in each of these thin slices – like monitoring and setting up deployment pipelines potentially. However, these steps shouldn’t take that long.
By slicing this thinly you can learn about your architecture and get the walking skelton in place relatively quickly. Therefore, understanding if you have any issues with the path you are taking.
You could then expand this out to another product or build out some other capability.
The take home is try to half what you do now, then once you get good at that, half it again. You should aim to get something delivered every day which extends your understanding of the problem domain.
My car went in to be serviced today, my wife takes it to the garage.
So that means I usually leave a note, if there are other problems with it. I’ve had an issue with my front head light. Last time I talked to them about it, they said it would probably be the bulb. I’d proved this not to be the case by changing the bulb from one head light to the other. I had to hand this information off, so I wrote a note.
During the day I got a call from the garage. The guy on the line wasn’t the mechanic doing the work, we had a garbled conversation about what the problem was, and what my note really meant. After about 2 minutes of not getting anywhere, he put the mechanic doing the work on. I managed to explain the investigation work I’d done, and my (google car expert) diagnosis of the issue.
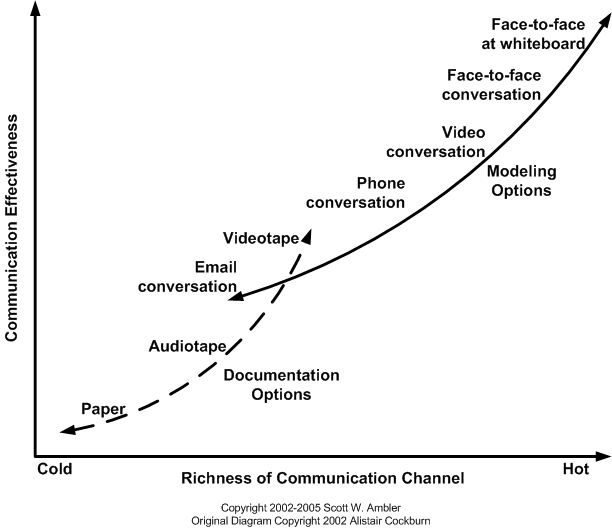
As my drive can be long home, I began to wonder about what had happened. It got me thinking about this diagram:
This has a couple of things:
I’d done some initial work – investigation and tried to express this in a note (hand off). Which was useless, it was only useful as a conversation starter. Maybe my badly written note would have been better “Front Headlight not working please call me”, rather than trying to describe what I’d done to investigate.
Why it’s important to talk to the person doing the work instead of a middle person.
Would it have been quicker face to face, with the car in front of both of us, to discuss.
We recently had some work to do which focused on getting stock more real time on the website. Here I’m going to take you on the journey of this piece of work.
We started with the above “requirement”, the real problem however, was subtle different – overselling on the website. This has the following impact on the customer and business:
The customer is annoyed because the order is cancelled, because it can’t be fulfilled
The cancellation process is slow, and is time consuming for Customer Services.
So how does stock get on the website? Stock is calculated every 5 minutes with a batch job then read in two ways on the website:
Through our search system
Through a direct call to our ERP system
The first slice was to make stock come from a single source, this would be easier to change in the future. So we set about reading the data directly from the ERP system and publishing this to our new stock service, then subsequently reading it in the website. This was live for a brand within a day or two. There was still some latency in this as we were still reliant on another batch job finishing before reading directly from the ERP system.
While delivering something quickly, this was the wrong slice as we didn’t really understand how we much we oversold by or when it happened (more on this later).
We started on the second obvious slice, making the stock real tiem, as we were still reliant on the batch job finishing for our stock levels to be up to date. We decided to “baseline” our stock and then just deal with “goods out” – i.e. what was sold on the site.
During this second slice, which was now much bigger, and more complicated. There were some product launches – this meant we had an opportunity to measure the impact of what we had been doing. We quickly realised that this second slice was wrong as we couldn’t measure the impact of it.
We pivoted to what our first slice should have been – understand overselling. We created numerous apps to let us monitor during these product launches so we could understand overselling. These where manual and needed us to watch them run. So after the first product launch, once we were happy this data was trustworthy. We enhanced these to not have to be manually run, so we monitor oversells and unknown product sales 24/7 now. We also started to capture when people entered the checkout on the website.
From this we could see a number of things about overselling:
About 80% of people where in our checkout; once we’d sold out
About 15% of people where still shopping on the site; once we’d sold out
About 5% where due to the non-real time nature of stock
Even if we’d completed our original second slice – “real time stock” we wouldn’t have solved the problem – overselling!
We came up with a list of things we could do, and worked with the stakeholder to narrow it down to the following:
Before placing the order – do a stock check
When people enter the checkout – do a stock check
Unfortunately, we’d already made another improvement which we didn’t know the impact of. Making the stock come from a single place. This was quantifiable as we’d not been measuring before we’d made any changes.
We made the changes outlined above and continuously released them and tried to monitor their impact.
We had some bad/good luck our new stock service started failing just before the weekend, so we had to turn it off. This was a blessing as we could now see how the site actually performed without any of our changes. Below is overselling over the weekend:
The coming weeks will be interesting as there are product launches, which tend to increase our overselling. Our plan is to monitor these and see if we need to do any more work.
Some things we learned:
Metrics – understand the problem & measure the impact of changes
Pivot quickly
Deliver every commit
Logging in apps – understand what your applications are doing, business and application wise
I’ve been recently talking to former colleagues about work. We discuss code and perceived quality in code. We tend to discuss the merits of good code and what it really looks like. Each time I come back to the same place in my mind. Good code is mainly about collective code ownership & having a shared understanding of what you are doing. So how does one go about helping manifest this?
I think software development is a 80/20 game… Depending on which you play it governs the impact on this collective code ownership and what some may deem as code quality.
If you work in the following manner 80% code and 20% communication – your code bases will all have a mish mash of styles, poor tests, good tests and really anything in between. Certain code will be well understood by certain people, and other bits will be understood a lot less by other people. Some people will open code bases and swoon at it’s clarity for them but others will open it up and want to instantly refactor it!
I’m more than convinced that working the other way 20% code and 80% communication gets a better shared code understanding. Now I don’t mean that you all sit around in meetings and discuss what good code looks likes. I suggest that you pair about 80% of your time, this is the communication piece that is lacking the other way around. This conversation drives a shared understanding through your code bases. It also helps ideas flow from mind to mind, while producing code to a certain degree.
Communication doesn’t just start or end with pairing, it starts by having the team be a team. This is something to focus on above and beyond everything else initially. Once you have this everything else will flow… More on this in another post.
Well I managed to get out to Lean Agile Manchester last night about Workplace visualisation and catch up with Carl Phillips of ao. We had an excellent burger in the Northern Quarter before heading over to madlab, therefore delaying our arrival – oops sorry guys! We spent quite a bit of time chatting about old times & then got down to the problem at hand.
Weirdly the first example was very reminiscent of where Carl & I started our journey at ao nearly four years ago. Although, some of the key points where slightly different – i.e. number of developers, the location of the constraints in the department.
A rough guide of the scenario:
Specialists with hand-offs, bottleneck in test, multi-tasking galore
Small changes and incidents getting in the way of more strategic projects
4 devs, 1 QA, 1 BA
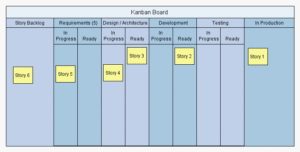
We came up with a board similar to this:
We introduced WIP limits around the requirements section and set this at 1 as testing tended to be the bottleneck. Reflecting this morning – introducing the WIP limits might have been a little premature…
As we where happy with the previous board, Ian challenged us to look at the digital agency scenario.
We started to map out the current value stream for the digital agency. A rough guide for the scenario:
Multitasking on client projects, fixed scope and deadlines,
lots of rework particularly because of UX
lots of late changes of requirements
3rd party dependencies and a long support handover for client projects
4 devs, 1 QA, 1 BA
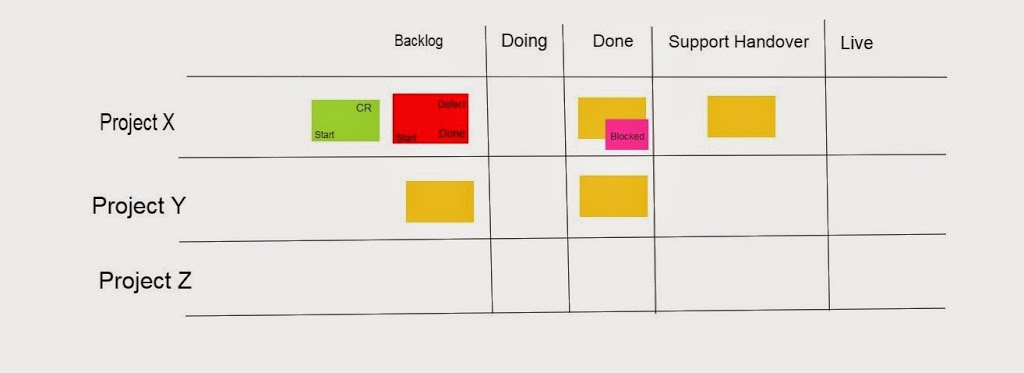
This time we used swim lanes. It looked similar but not exactly like this:
These actually added inherent WIP limits because a swim lane could only have one card in within the column. We introduced different two additional classes of service (we had a “feature” class of service for project work):
A defect which blocked the current ticket and got tracked across the board.
CR’s which would track across the board too.
We had a differing opinion on whether the “client support hand over” should be an additional column or a ticket – we ended up going with a column.
What I realised about this second scenario was that we mapped what was currently happening, although we introduced some inherent WIP limits due to board layout, but these where not forced upon the board – i.e. with numbers above the card columns.
Visualisation is good first step on understanding how work flows through a system, but remember to not force concepts on to the current environment. “Start with what you do now”.
A couple of years ago I would have told you that if you are accessing the a database you need a repository pattern. This allows you to hide away your data access code behind a nice interface – then at least you can mock the data access layer and change your data access code if you ever wanted to do that.
So say we are in a web application and want to get a “customer” by a specific reference. This is how we would do it with the repository pattern…
How different my opinion is today. I can’t help but feel that the pedal pushed repository pattern (in the C# .Net world) that is on the internet is fundamentally broken. The key thing for me is that everyone seems to want to create the following interface:
public interface IRepository<TEntity, in TKey> where TEntity : class { IEnumerable<TEntity> GetAll(); TEntity GetBy(TKey id); void Save(TEntity entity); void Delete(TEntity entity); }
Not bad so far hey? This seems pretty “standard” apart from the fact you’ve broken single responsibility (SRP). How many responsibilities does the IRepository already have – 4 public methods which do very different things…
The other thing I’ve found is that things can & generally will get worse from here – then follows:
public class Repository<TEntity, TKey> : IRepository<TEntity, TKey> where TEntity : class { private readonly IUnitOfWork _unitOfWork; public Repository(IUnitOfWork unitOfWork) { _unitOfWork = unitOfWork; } public IEnumerable<TEntity> GetAll() { return _unitOfWork.Session.QueryOver<TEntity>().ToList(); } public TEntity GetBy(TKey id) { return Session.QueryOver<TEntity>().FirstOrDefault(x => x.Id == id); } public void Save(TEntity entity) { } public void Delete(TEntity entity) { } }
So now all you need to do to get access to something is as follows:
public class CustomerRepository : Repository<Customer, int>, ICustomerRepository { public CustomerRepository(IUnitOfWork unitOfWork) : base(unitOfWork) { } }
Does this look familiar? It does to me – I’ve done this and I’m pretty sure its wrong!
Again there are a couple of things that appear wrong:
SRP is broken
What happens if you’ve got a complicated queryable object and you are using an ORM – you’ll end up with lots of SELECT N+1.
We’ve over complicated a simple task with – 3 interfaces, a base class (coupling), and 2 classes.
If you want to read from one data store and write to another data store how would you do this?
We’ve introduced so many layers and complexity that it seems that even to do a simple thing it’s been massively over complicated. I’ve forgot to show you the IUnitOfWork which is equally badly suggested and implemented on the internet…
Now for the alternative:
var customer; using(var transaction = Session.BeginTransaction()) { customer = Session.QueryOver<Customer>().FirstOrDefault(x => x.Id == customerId) ?? new NullCustomer(); transaction.Commit(); }
Wow, is this simple or what? But what about testing? Well I tend to use NHibernate with an InMemoryDatabase so I don’t have to mock the data access layer… I don’t tend to use mocks but that’s another story… The code is simple and clear.
Now if things advanced and I wanted to put it in a class then I’d put it behind something that only reads customer information:
public class ReadCustomers { private ISession _session; public ReadCustomers(ISession session) { _session = session; } public Customer GetBy(int customerId) { var customer; using(var transaction = _session.BeginTransaction()) { customer = _session.QueryOver<Customer>().FirstOrDefault(x => x.Id == customerId) ?? new NullCustomer(); transaction.Commit(); } return customer; } }
Again with storing information if you really wanted to push it in a class then something like this:
public class StoreCustomers { private ISession _session; public StoreCustomers(ISession session) { _session = session; } public void Add(Customer customer) { using(var transaction = _session.BeginTransaction()) { _session.SaveOrUpdate(customer); transaction.Commit(); } } }
The classes have clear responsibility & a single responsibility – you can even easily change where you read and write data from and too! Plus the code is much simpler and easier to optimise.